Neural Radiance Fields
희소한 이미지 뷰를 통해, 연속적인 Volumetic scence 함수를 최적화 하여 새로운 뷰를 합성하고 영상을 만들어냄.
Algorithm
1) Fully connected deep network (non - convolutional)
2) input : a single continuous 5D coordinate (x,y,z,θ,φ)
3) output : volume density and view - dependent RGB color , 4D
4) volume rendering techniques
=> 복잡한 외관을 가진 장면을 사실적으로 렌더링하기 위해,
NeRF를 효과적으로 최적화하는 방법을 설명하고 Neural Randering 및 뷰 합성에 대한 우수한 결과 보여줌.
자연 환경에서 찍은 RGB 이미지에서 실제 물체와 장면의 고해상도 포토리얼리즘적 새로운 뷰를 렌더링할 수 있는
최초의 Continuous neural scene representation을 제시한다.
Introduction
이미지 세트의 렌더링 오류를 최소화 하기 위해
연속적인 5D scene 표현의 파라미터를 직접 최적화하여
새로운 방식으로 뷰 합성 개발
NeRF를 특정 시점으로 렌더링 하기 위해 다음 과정 거침
1) 카메라 광선을 장면에 투과하여 샘플링된 3D 포인트 세트 생성 (Ray casting)
Ray casting
Volume Rendering 기술 종류 중 하나로,
2차 평면의 픽셀 하나하나로 광선을 쏜다고 가정하고 그 광선상에 위치되는
모든 Voxel의 색상을 합하여 해당 픽셀을 그리겠다는 것.

2) 해당 포인트와 해당 2D 시각 방향을 신경망의 입력으로 사용하여 색상과 밀도의 출력 세트 생성
3) 고전적인 Volume rendering techniques를 사용하여 색상과 밀도를 2D이미지로 축적
[gradient descent 활용하여 model을 최적화 진행]
==> 각 관찰된 뷰와 Representation 뷰에서 렌더링된 해당 뷰 사이의 오차 최소화.
==> Neural Network가 실제 장면이 포함된 위치에 높은 Volume density와 정확한 색상을 할당하여 일관된 모델 예측 가능
문제점
- 카메라 Ray 당 필요한 샘플 수가 비효율적이라는 사실 발견
- 복잡한 씬에 대해 NeRF를 최적화하는 기본 구현은 높은 해상도의 표현으로 수렴되지 않음
해결방안
1. Positional Encoding
- input 5D coordinates를 positional encoding으로 변환하여 MLP가 더 높은 frequency function로 표현할 수 있게 함.
2. A Hierarchical sampling procedure
- 적절히 샘플링하는 데 필요한 쿼리 수를 줄였음.
==> 고해상도에서 복잡한 장면을 모델링할 때 이산화된 복셀 그리드의 엄청난 저장 비용을 극복함.
Related Work
Neural 3D shape representations
-(Recent work) : Signed distance function 또는 Occupancy field에 xyz좌표를 매핑하는 deep networks를 최적화하여 연속적인 3D도형을 Level set으로 표현하는 방법
단점 : 실제 3D 도형을 통해서 학습하고 최적화해야함.
-(Subsequent work) : 실제 3D 형상에 대한 요구사항을 완화하기 위해 미분 가능한 렌더링 함수를 제시하여 2D 이미지만 사용하여 최적화할 수 있게 함.
[Niemeyer et al의 연구]
각 ray 교차점을 찾기 위해 수치적인 방법을 사용하고 implicit differentiation을 통해 정확한 도함수 계산
각 ray 교차점 위치는 신경망 3D 텍스처 필드에 입력으로 제공되면, 해당 위치의 색상을 예측함
[Sitzmann et al의 연구]
보다 직접적이지 않은 3D network 사용. 각 연속적인 3D 좌표에서 특징 벡터와 RGB 색상을 간단히 출력함.
각 광선을 따라 진행하는 재귀적 신경망으로 이루어진 미분 가능한 렌더링 함수 제안함. 이 함수는 표면의 위치를 결정하는데 사용됨.
-(NeRF) : Network 최적화를 통해 5D radiance fields를 인코딩하도록 대체 , 높은 해상도와 복잡한 장면의 사질적인 새로운 시점을 렌더링 가능
View synthesis and image-based rendering
- (Mesh-based representations) : Mesh 기반 표현을 사용하는 접근 방식 -> 미분 가능한 resterizers와 패스트레이서 같은 기술을 사용하여 Mesh 표현 최적화 => 입력 이미지 집합 재현
=>이미지 투영(image reproduction) 기반으로 한 경사 하강법(gradient descent)을 사용하여 Mesh를 최적화하는 기법 존재
문제점 : local minima 와 손실함수의 landscape가 최적화하기 어려운 상태 + template mesh with fixed topology => 실제 환경의 장면에서는 사용하기 어려움
- (Volumetric representations) : 다수의 장면으로 구성된 대규모 데이터셋으로 deep network를 훈련시켜 샘플링된 volume 표현 예측 , test시에는 합성을 사용하여 새로운 시점 렌더링 하는 등의 여러 방법 제안됨.
문제점 : 이런 볼륨 표현 기법들은 높은 해상도 이미지로 확장하는데 어려움이 있음
- (NeRF) : deep fully-connected neural network의 parameters내에 연속적인 volume을 인코딩함으로써 위 문제 해결.
Neural Radiance Field Scene Representation

Input
: 3D location x = (x,y,z) & 2D Viewing Direction (θ,φ)
Output
: Color c = (r,g,b) & Volume Density σ
(a) : 카메라 ray을 따라 5D coordinates 를 샘플링함.
(b) : MLP 에 입력하여 (r,g,b) & σ 를 생성함.
(c) : Volume Rendering Techniques를 사용하여 이러한 값을 이미지로 합성.
(d) : 이 렌더링 함수는 미분 가능하므로 합성된 이미지와 실제 관측 이미지 간의 오차를 최소화함으로써 장면 표현 최적화 가능.
Network
(volume density σ) : location x로만 예측하도록 제한
(RGB color c) : location x와 viewing direction d 모두로 예측할 수 있게 함.

!!!gt값에 대해서 방향에 따라 빛이 반사되어 하얗게 보이는 부분까지 rendering 할 수 있다.
& 고정된 점에 대해서 view위치를 바꿔가면서 찍었을 때 연속된 color변화를 표현할 수 있다.!!!
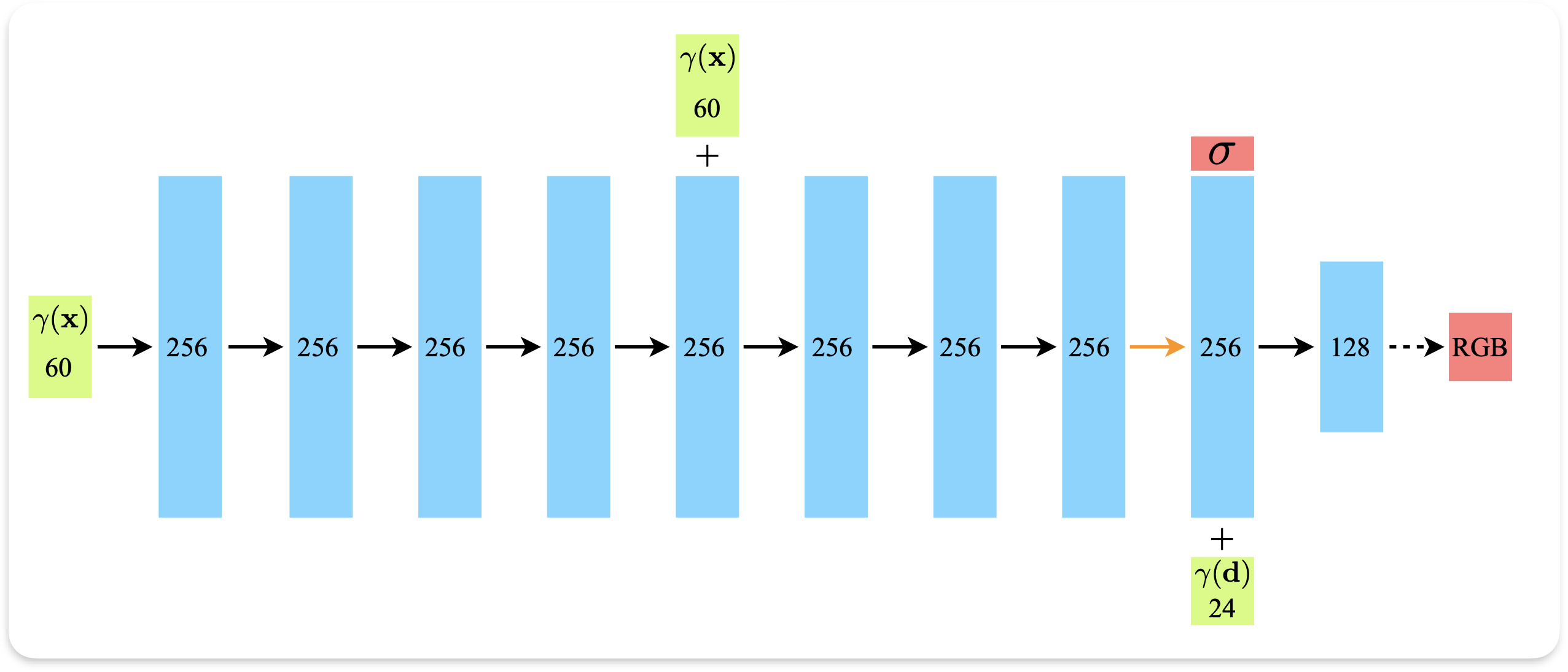
(Fully-connected architecture)
1. Input : 3d location x
2. 8개 fully connected layer(ReLU 사용 , 256 채널)로 처리
3. σ 과 256 feature vector 출력
4. 출력된 256 feature vector + direction d 와 연결
5. 하나의 추가된 fully connected layer (ReLU , 128채널) 로 전달
6. Output : RGB
Positional Encoding

- Transformers 에서 사용되는 Positional Encoding과는 조금 다른 의미를 가진다.
- Input 데이터인 (x,y,z,θ,φ) 5차원은 데이터의 정보량이 부족함. (feature가 부족하다는 의미와 같다고 생각하면됨.)
- 차원을 늘려주기 위해 Positional Encoding을 사용함.
- sin, cos function 사용
- L : hyper parameter
- R => R^2L 차원으로 향상시킨다. 즉 , 2L만큼 올라간다.
- L = 10 : γ(x)에서 사용, xyz각각 2L만큼 커지므로 ==> 60차원
- L = 4 : γ(d)에서 사용, (θ,φ,lay에서 통과된 vector) 각각 2L 만큼 커지므로 ==> 24차원
FΘ = FΘ′ ◦ γ
위 합성함수로 정의하여 neural network에 넣었을 때, 더 high-frequency 변동을 더 효과적으로 학습하고 표현할 수 있다고 제시한다.
=> 이런 고차원의 값이 더 잘 적합시킨다고 보여준다.
Volume Rendering with Radiance Fields
Volume Rendering?
- 3차원 정보의 텍스쳐를 활용하여 3차원의 꽉 찬 객체를 컴퓨터 화면 상(2d)에 그리는 일
> Texture Slicing : CT 촬영 처럼 slicing된 2d 이미지를 합쳐서 하나의 3d 객체로 만드는 방법
> Ray casting : 2d 이미지의 픽셀마다 광선을 하나하나 쏜다고 가정하고 그 광선상에 위치되는 모든 Voxel의 색상을 합하여 해당 픽셀을 그리는 방법

> r(t) = o + td 를 통해서 ray 를 쏘게 된다. o : camera 원점 좌표 , t : 얼마나 뻗어나간 좌표인지 , d : direction (θ,φ)
> c(r(t),d) => RGB 값 ( neural network 를 통해 얻음 ) : particle 의 위치에 대한 색상 값
> σ(r(t)) => density 값 ( neural network 를 통해 얻음 ) : particle의 위치에 대한 density 값으로 얼마큼 색상값을 픽셀에 부여할 것인지 관여
> T(t) : tn에서 t까지 ray를 따라 누적된 density 값을 말함.
(즉, ray가 다른 입자에 부딪히지 않고 tn에서 t까지 이동할 확률을 나타낸다.) 얼마큼 색상값을 픽셀에 부여할 것인지 관여
앞에 있는 t들의 density 값들이 크다면 해당 t의 density는 무시해줘야하기 때문에 값을 낮춰야한다. (-를 곱한 이유) , exp는 적분하다보면 값이 커지므로 작게 만들기 위해 해놓은 듯 싶다.

[계층화 샘플링 접근 방식(Stratified sampling approach)]
> tn에서 tf를 N으로 동일하게 간격을 두어 나눈 다음, 각 부분 내에서 균등하게 무작위로 하나의 샘플을 추출

(1) 식은 continuous한 데이터를 적분하여 rendering 할 때 사용하는 식이고
(3) 식은 discrete한 값을 적분할 때 사용하는 시그마 식이다.
이를 사용하기 위해,density 값을 (1 − exp(−σiδi))으로 바꾸어 활용한다. Max가 1995년도에 발표한 논문에서 사용한 방법론으로 density값을 discrete하게 바꾸는데 사용하는 식이다.
t 값은 계층화 샘플링 접근 방식을 활용하여 discrete하게 바꾼다.
Hierarchical volume sampling
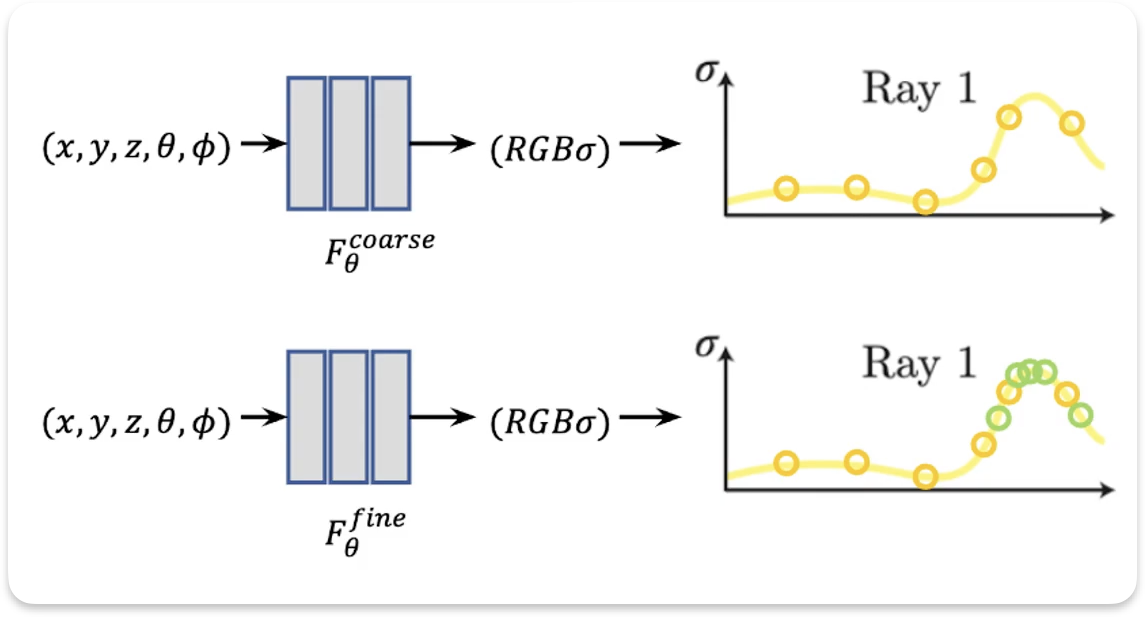
NeRF MLP model : coarse network & fine network.
- coarse network : 처음 Nc개 sampling 후, 진행.
- fine network : coarse에서 얻은 높고 낮은 density 부분중 높은 density부분을 중점적으로 다시 Nf개 sampling 후 진행.
(렌더링 결과에 더 많은 영향을 미칠 것으로 예상되는 영역에 더 많은 샘플을 할당함)
최종 사용 sampling : Nc + Nf
[과정]
1. coarse network 진행
2. Weight normalize를 통해 PDF 생성

확률 밀도 함수( probability density function )
Weight 를 확률 분포(확률)라고 보고 c(r(t),d)를 확률 변수라 생각하여 생성.
3. Nf를 inverse transform sampling
Inverse Transform Sampling (역변환 샘플링)
[과정]
1. 누적 분포 함수 (CDF) : 원하는 확률 분포의 누적 분포 함수 계산
2. 균일 난수 생성 : 구간 [0,1]에서 균일 분포에 난수 U를 생성
3. 역 CDF 적용 : CDF의 역함수, F^(-1)(U) 를 사용하여 균일 샘플을 원하는 분포로 변환

4. Nc+Nf
5. fine network 진행.
Rendering Loss
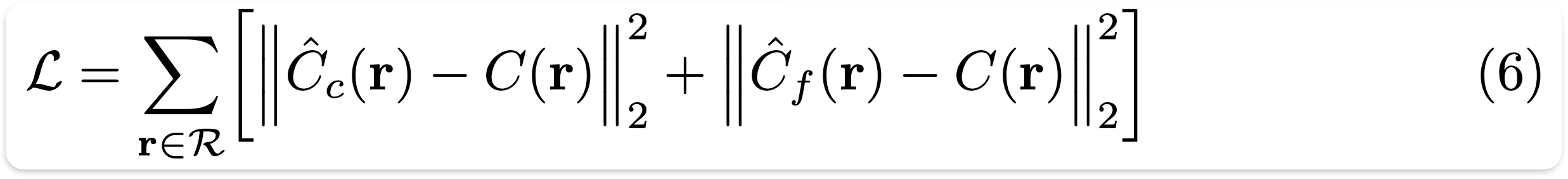
Rendering Loss
- coarse network에서 렌더링 된 색상과 fine network에서 렌더링 된 색상 각각을 실제 픽셀 색상간의 total 제곱 오차 값으로 계산.
Each optimization iteration
: randomly sampling a batch of camera rays -> hierarchical sampling Nc + Nf -> volume rendering -> computing loss
4096 rays, Nc = 64, Nf = 128.
The optimization for a single scene typically takes around 100-300k iterations to converge on a single Nvidia V100 GPU(about 1-2 days)
After Work
RegNeRF
적은 image들을 통해서도 NeRF 보다 비교적 깨지지 않고 잘 continuous하게 생성한다는 점이 특색임.
Regularize Geometry & Regularize Color 를 진행하여 앞에도 매끈하면 뒤에도 매끈할 것이다!
세상에는 매끈한 객체들이 많다. + 앞에도 초록색이면 뒤에도 초록색일 것이다.의 가정으로 시작.
Instant NeRF(=INGP)
- Original NeRF의 단점중 느린 속도부분을 해결하였다. (Instant NGP라고도 함.)
- Positional encoding 대신에 Multi-resolution Hash Encoding 적용
=> 보다 빠르게 NeRF 학습 &해상도 높음
- 추가로, CUDA, c++기반의 cuda tiny nn library 와 Simple MLP를 통해 더 빠른 속도 가능.
- 최대 1000배 이상 빠른 속도 , GPU 1개만 사용하여 학습하였다고 함.

Mip NeRF 360
[Mip NeRF]
- Single ray가 아닌 3D cone을 사용하여 pixel을 casting 함. (Ray casting X) => Mip NeRF에서 착안.
- Integrated Positional Encoding 사용
- 하나의 ray가 아닌 cone 형태로 형성되다보니, mipmap의 아이디어를 차용
- Ray위의 point를 positional encoding하지 않고 conical frustum(원뿔 절단제, texture 형태)를
- Gaussian 확률 밀도 함수를 Encoding함수로 정의함.
- mipmap 형태를 착안하였기에 빠른 렌더링 속도와 용량 최소화 , 자연스러운 렌더링 효과 보여줌
[Mip NeRF 360]
- unbound scene(제한 없는 확장 가능한 공간)에서 Normalized기법을 사용함.
- Integrated Positional Encoding을 normalize함.

Zip NeRF
- 퀄리티 관점에서 top인 Mip NeRF360와 속도 관점에서 Top인 iNGP의 장점을 조합한 연구
- Mip NeRF 360의 Integrated Positional Encoding 사용
- iNGP의 Grid-based 모델링으로 3D coordinate에 대한 부분 사용

NeRF 세부 정리본 (마인드맵 형식)
다음 paper review는 Zip NeRF를 진행해볼 예정이다.