한국어로 흔히 객체 인식으로 불리는 object detection은 다양한 모델로 구현이 가능하다. 이 다양한 모델의 장단점과 차이점을 구분하는 공부과정을 가져보았다.
Object Detection
Computer vision의 다양한 분야중 하나로, 주어진 이미지에서 사용자가 원하는 객체를 인식하고 찾아내는 기술이다.
<여기서 Classification과 Object detection의 차이가 무엇일까?>
-Classification은 이미지내에 있는 객체를 분류하고 판별만 하는 것이고 Object Detection은 판별하는 동시에 객체가 어디에 위치해있는 지까지 탐지하는 것이다.
다시말해, Object Detection은 어떤 객체인지 분류(Classification)하고 그 객체가 어디에 있는지 좌표를 통해 찾아내는(Localization)의 이슈를 해결해야하는 기술이다.
Object Detection은 자율주행, 차량번호인식, 온도체크 사람인식 등 다양한 분야에서 사용되고 있다.
1-Stage Detector VS 2-Stage Detector
Deep Learning Object Detection은 1-stage Detector 또는 2-stage Detector로 나뉜다.
Region Proposal 은 물체가 있을만한 영역을 빠르게 찾아내는 알고리즘,
Classification은 특정 물체에 대해 어떤 물체인지 분류하는 알고리즘.
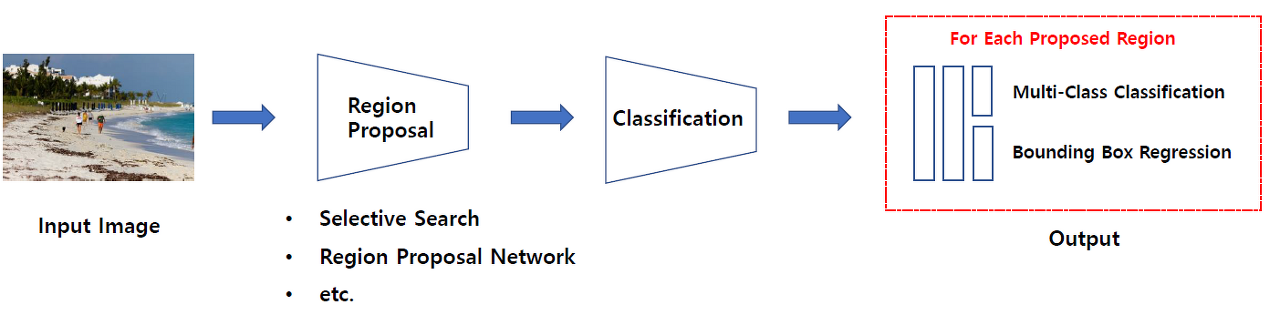
2-stage Detector는 위 사진으로 알 수 있듯, Localization(Region Proposal)과 Classification을 순차적으로 진행을 한다.
비교적 느리지만, 정확도가 높다.
이 방법에는 R-CNN (Fast R-CNN, Faster R-CNN 등) 계열이 포함되어있다.

1-stage Detector는 위 사진으로 알 수 있듯, Conv Layer를 통해 이미지 특징을 추출하여 Localization과 Classification을 동시에 진행하는 방법이다.
비교적 빠르지만, 정확도가 2 stage보다 낮다.
이 방법에는 YOLO(you look only once) 와 SSD 계열이 포함되어있다.
R-CNN

R-CNN은 Selective Search를 이용해 이미지에 대한 후보영역(Region Proposal)을 생성한다.
Selective Search란, object 인식이나 검출을 위한 가능한 후보 영역을 알아낼 수 있는 방법을 제공하는 것을 말한다.
과정으로는,
1. 입력 영상에 대해 segmentation을 실시해서 이를 기반으로 후보 영역을 찾기 위한 seed를 설정
2. 초기에 엄청나게 많은 후보들이 만들어진다.
3. 이를 적절하게 통합해 나가면, segmentation은 후보 영역의 개수가 줄어들고, 결과적으로 이를 바탕으로 box의 후보 개수도 줄어든다.
고려사항에는 크기 색상, 질감, parts 등이 있다.

아래 링크에서 자세히 설명해주니 참고하면서 공부해보자.
https://better-tomorrow.tistory.com/entry/Selective-Search-간단히-정리
Selective Search 간단히 정리..
Selective Search - 기존의 exhaustive search의 방식의 비효율성으로 "object가 있을 법한 영역만 찾는 방법"이 제안됨 - 이를 region proposal - 이 후 detector는 1) generic detector로 candidate obj..
better-tomorrow.tistory.com
selective Search를 통해 얻은 후보영역들을 고정된 크기로 바꿔서 CNN에 넣는다.
CNN에서 나온 Feature map으로 SVM으로 Calssification하고, Regressor을 통해 Bounding-box를 조정한다.
강제로 크기를 맞춰서 CNN에 젛기 때문에 이미지 손실이 일어날 수 있고 후보영역을 모두 CNN에 돌려야하기 때문에 느리고 저장공간이 많이 필요하다.
Fast R-CNN

각 후보영역을 먼저 선정하는 것이 아닌, 영상 전체에 CNN을 적용하여 생성된 Feature map에서 후보영역을 선출한다.
이 후보영역(Region Proposal)은 Rol Pooling을 통해 고정 사이즈의 Feature vector로 추출한다.
이 Feature vector에 FC layer를 거쳐 softmax를 통해 classification을, Regressor를 통해 Bounding-box를 조정한다.
Faster R-CNN

Fast R-CNN 과 R-CNN에서 후보영역을 추출할 때는 selective search를 사용하였다.
Faster R-CNN에서는 후보영역을 생성하는 작업과 object detection이 동일한 CNN에서 진행된다.
region proposal을 생성하는 방법을 selective search가 아닌 CNN(즉, RPN라고도 부름)을 통해 후보영역을 생성하고 object detection도 수행한다.
이런 설계로 detection 속도가 빨라지게 된 것이다.

Feature map에 sliding window를 사용하여 Intermediate Layer를 생성한 후, 두개의 conv를 적용하여 classification와 regression 으로 나눠진다. Classification은 object가 존재할 확률, regression은 bounding box의 좌표를 출력한다.
RPN으로 얻은 후보 영역을 IoU순으로 정렬하고 NMS(Non-Maximum Supperssion)알고리즘을 통해 최종 box를 선정한다.
선정된 box의 크기를 맞추기 위해 Rol Pooling을 거치고 softmax와 regressor을 동일하기 진행한다.
YOLO(You Only Look Once)

Bounding box와 Classification을 하나의 문제로 간주하는 1 stage detector의 대표적인 모델이다. 객체의 종류와 위치를 한번에 예측한다. 이미지를 일정 크기의 greed로 나눠 각 그리드에 대한 Bounding box의 confidence score와 그리드셀의 class score의 값으로 학습하게 된다.
간단한 처리과정으로 속도가 매우 빠르지만 작은 객체에 대해서는 상대적으로 정확도가 낮다.
SSD(Single Shot MultiBox Detector)

Convolutional Layer 이후에 나오는 Feature map마다 Bounding Box의 Class 점수와 좌표를 구하고, NMS 알고리즘을 통해 최종 Bounding Box를 결정한다. 이는 각 Feature map마다 스케일이 다르기 때문에 작은 물체와 큰 물체를 모두 탐지할 수 있다는 장점이 있다.
'Data_study > Deep Learning' 카테고리의 다른 글
| [Deep learning] Backpropagation & Chain Rule 개념 (0) | 2023.04.04 |
|---|---|
| [Deep learning] Precision & Recall & IoU (0) | 2022.10.01 |
| [Deep learning] Conv Layers (0) | 2022.08.13 |
| [Deep_learning] Multiclass_Classifiers 구현 (0) | 2022.07.12 |
| [Deep_learning] Binary Classifiers 구현 (0) | 2022.02.23 |