Programming3 Project
: 노트북 데이터를 활용하여 사용자가 원하는 조건의 노트북들을 비교 분석하기
>프로젝트 주제 선정 이유
: 노트북과 같이 다양한 스펙을 갖는 데이터가 있는 제품을 구매하고자 할때,내가 원하는 스펙의 조건중 가장 합리적인 제품인 무엇인지 결정하는데에는 많은 어려움이 있다.
현재 네이버나 다나와 쇼핑몰에서는 cpu와 제조사, 화면 크기, 메모리, 저장 용량, 무게까지는 원하는 스펙을 선택하여그에 맞는 제품을 확인할 수 있도록 구성되어 있지만, GPU나 배터리, HDMI 포트 유무, 두께, 웹캠 유무처럼섬세한 스펙은 선택하여 볼 수 없다.
따라서 이런 부족한 부분을 보완하여 소비자가 자신에게 적합한 노트북을 선택할 수 있도록도와주는 시스템을 구축하는 것이 본 프로젝트 주제 선정의 목표다.
>데이터 소개
- 다나와 쇼핑몰에서 노트북를 검색하여 나오는 페이지와 각 노트북 상세 페이지에서 크롤링 진행

Data Crawling
: 다나와 쇼핑몰에서 '노트북'을 검색하여 인기상품목록을 크롤링하였다.
import pandas as pd
import numpy as np
matplotlib.rc('font', family='Malgun Gothic')
import matplotlib.pyplot as plt
import seaborn as sns
import re
import time
plt.rcParams['axes.unicode_minus'] = False
from selenium import webdriver
from selenium.webdriver import Chrome
from selenium.webdriver import ChromeOptions
from bs4 import BeautifulSoup
options = ChromeOptions()
options.add_argument('headless')import numpy as np
item_list = []
want_title = ["화면 크기","CPU 종류","운영체제(OS)",'화면 비율','광시야각','메모리 타입','메모리','저장 용량','저장장치 종류','GPU 칩셋','HDMI','웹캠(HD)','배터리','어댑터','두께','무게','USB','ㅗ형 방향키','ㅡ형 방향키']
for page in range(1,10): #몇 페이지 까지 할 것인지 range 결정
print('\n',page)
url = "http://search.danawa.com/dsearch.php?query=%EB%85%B8%ED%8A%B8%EB%B6%81&originalQuery=%EB%85%B8%ED%8A%B8%EB%B6%81&previousKeyword=%EB%85%B8%ED%8A%B8%EB%B6%81&volumeType=allvs&page="+str(page)+"&limit=40&sort=saveDESC&list=list&boost=true&addDelivery=N&recommendedSort=Y&defaultUICategoryCode=112758&defaultPhysicsCategoryCode=860%7C869%7C10586%7C0&defaultVmTab=85012&defaultVaTab=7076658&tab=goods"
driver = Chrome(executable_path='Downloads/chromedriver')
driver.get(url) #셀레니움의 chrom 웹드라이버로 창 열기
soup = BeautifulSoup(driver.page_source) #셀레니움으로 들어간 웹 창에서 beautifulSoup으로 크롤링 진행
#각 제품의 이름이 있는 부분들 모두 크롤링
product_li_tags = soup.select('p.prod_name a.click_log_product_standard_title_')
num = 0
#for 문으로 하나하나 제품들 정보 크롤
#한 제품의 정보들을 임시로 담아둘 list 생성
item_one_list = []
#제품 이름 크롤링
name = tg.get_text()
item_one_list.append(name)
#제품 링크 크롤링 후 그 링크로 다시 창 띄우기 -> 상세 페이지 크롤링 진행
link = tg.attrs['href']
url_item = link
driver_item = Chrome(executable_path='Downloads/chromedriver')
driver_item.get(url_item)
soup_item = BeautifulSoup(driver_item.page_source)
#제품 상세정보 제목들 크롤링
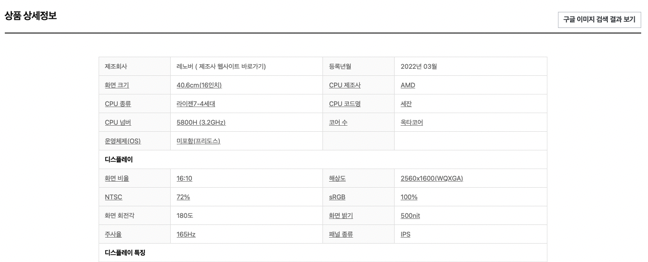
item_inpo_title = soup_item.select('div.detail_cont div.prod_spec table th.tit')
#제품 상세정보 정보들 크롤링
item_inpo_value = soup_item.select('div.detail_cont div.prod_spec table td.dsc')
#제품 최저가 크롤링
product_price = soup_item.select('div.row span.lwst_prc em.prc_c')
item_one_list.append(product_price[0].get_text()) #제품 가격이 사이트 별로 많아서 첫번째 가격(최저가)으로 크롤링
#상세정보에서 제조사에 두 문자열이 포함되어 있어, 크롤링 하기 힘들어 지워주었다.
del item_inpo_title[0]
del item_inpo_value[0]
#위에서 제품 상세정보 제목들 & 정보들 크롤링한 것을 list에 모두 넣어두고 아래에서 indexing 진행
item_inpo_title_list = []
item_inpo_value_list = []
for tit,val in zip(item_inpo_title,item_inpo_value):
title = tit.get_text()
value = val.get_text()
item_inpo_title_list.append(title)
item_inpo_value_list.append(value)
#상세정보에서 원하다고 list 만들어놓은 want_title 요소들을 추출
for i in want_title:
if i in item_inpo_title_list:
item_one_list.append(item_inpo_value_list[item_inpo_title_list.index(i)])
else:
item_one_list.append(np.nan)
#한개의 제품에서 필요한 정보들을 넣어둔 item_onelist를 tuple형태로 item_list에 넣기
item_list.append(tuple(item_one_list))
print(num,end=' ')
num += 1 #어디까지 크롤링 진행됐는지 확인> 위 크롤링 과정이 오래걸리므로 dataframe형태로 만들어 csv파일로 저장하였다.
#모두 담겨진 item_list를 해당 columns을 setting하여 dataframe으로 변환.
df_item = pd.DataFrame(item_list, columns = ['제품명','가격',"화면 크기","CPU 종류","운영체제(OS)",'화면 비율','광시야각','메모리 타입','메모리','저장 용량','저장장치 종류','GPU 칩셋','HDMI','웹캠(HD)','배터리','어댑터','두께','무게','USB','ㅗ형 방향키','ㅡ형 방향키'])
#notebooks_final로 저장.
df_item.to_csv("data_story/Programming3/notebooks_final.csv", mode='w')df_item.info()#위 info()출력값
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 360 entries, 0 to 359
Data columns (total 21 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 제품명 360 non-null object
1 가격 360 non-null object
2 화면 크기 360 non-null object
3 CPU 종류 360 non-null object
4 운영체제(OS) 360 non-null object
5 화면 비율 354 non-null object
6 광시야각 281 non-null object
7 메모리 타입 350 non-null object
8 메모리 360 non-null object
9 저장 용량 360 non-null object
10 저장장치 종류 360 non-null object
11 GPU 칩셋 353 non-null object
12 HDMI 225 non-null object
13 웹캠(HD) 266 non-null object
14 배터리 351 non-null object
15 어댑터 306 non-null object
16 두께 360 non-null object
17 무게 360 non-null object
18 USB 358 non-null object
19 ㅗ형 방향키 304 non-null object
20 ㅡ형 방향키 56 non-null object
dtypes: object(21)
memory usage: 59.2+ KB2. Data Preprocessing
데이터 값 수정 & 형 변환
크롤링한 데이터를 보기 좋게 변환하기
notebooks = pd.read_csv("data_story/Programming3/notebooks_final.csv",index_col = '제품명')
notebooks = notebooks.drop(columns=['Unnamed: 0'])notebooks.head()
#데이터를 분석하기 좋게 값들과 형을 변환해주었다.
def preprocessing_data(df):
# ㅗ형 방향키 & ㅡ형 방향키 수정
# na가 아닌 값이 있는 ㅗ형 방향키와 ㅡ형 방향키 값을 더하면 360개라서(즉, 두 열에 존재하는 값을 더하면 결측치가 없는 열을 만들 수 있다.)
# ㅗ형 방향키는 값이 있고 ㅡ형 방향키에는 값이 없으면, '1',
# ㅡ형 방향키는 값이 없고 ㅡ형 방향키에는 값이 있으면, '0'으로 되어있는 열을 생성
make_wk_list = []
for wk1,wk2 in zip(df['ㅗ형 방향키'].fillna('0'),df['ㅡ형 방향키'].fillna('0')):
if (wk1 == '0') & (wk2 != '0'):
make_wk_list.append('0')
elif (wk1 != '0') & (wk2 == '0'):
make_wk_list.append('1')
else:
make_wk_list.append(np.nan)
make_wk = pd.DataFrame(make_wk_list,columns = ['방향키(ㅡ형/ㅗ형)'],dtype = 'category')
#USB 열 수정
#'n개'형태로 되어있는 값에서 n만 추출하여 값으로 지정함. dtype은 int8로 변환
def pre_usb(val):
if val == '0':
return val
else:
return val[1:-1]
make_usb = df['USB'].fillna('0').apply(pre_usb).rename('USB(개)').astype(np.int8)
#무게 열 수정
#'nkg'형태로 되어있는 값에서 n만 추출하여 값으로 지정함. dtype은 float64로 변환하고 소숫점 2째자리까지만
def pre_kg(mm):
if mm[-2:] == 'kg':
return mm[:-2]
else:
return str(float(mm[:-1])*0.001)
make_kg = df['무게'].fillna('0').apply(pre_kg).rename('무게(kg)').astype(np.float64).round(2)
#어댑터 열 수정
#'nW'형태로 되어있는 값에서 n만 추출하여 값으로 지정함. dtype은 float64로 변환하고 소숫점 2째자리까지만
def pre_ad(ad):
if ad =='0':
return np.nan
else:
return ad[:-1]
make_ad = df['어댑터'].fillna('0').apply(pre_ad).rename('어댑터(W)').astype(np.float64).round(2)
#HDMI 열 수정
#'○'값은 1로 결측치는 '0'으로 지정.
make_hdmi = df['HDMI'].fillna('0').replace('○','1').astype('category')
#저장 용량 열 수정
#저장 용량에는 1tb와 2tb 4tb도 있어서 기본 단위는 GB로 하고 TB는 1tb = 1024 ,2tb = 2048로 변환해주었다.
def pre_sm(sm):
msm = sm[:-2]
if msm == '1':
return msm+'024'
elif msm == '2':
return msm+'048'
elif msm == '4':
return msm+'096'
else:
return msm
make_sm = df['저장 용량'].apply(pre_sm).rename('저장 용량(GB)').astype(np.int16)
#메모리 열 수정
#'nGB'형태로 되어있는 값에서 n만 추출하여 값으로 지정함. dtype은 int16로 변환
def pre_mem(mem):
return mem[:-2]
make_mem = df['메모리'].apply(pre_mem).rename('메모리(GB)').astype(np.int16)
#두께 열 수정
#'nmm'형태로 되어있는 값에서 n만 추출하여 값으로 지정함. dtype은 float64로 변환하고 소숫점 2째자리까지만
make_mm = df['두께'].apply(pre_mem).rename('두께(mm)').astype(np.float64).round(2)
#가격 열 수정
#중간중간에 ,를 지워주고 dtype는 int32로 변환
def pre_pri(pr):
return pr.replace(',','')
make_pr = df['가격'].apply(pre_pri).astype(np.int32)
#화면크기 열 수정
#인치 숫자만 추출하기 위해 앞에 cm단위 값들고 '('')'값들을 모두 없애주고 dtypesm는 category로 변환
def pre_ds(ds):
return float(ds.split('(')[-1][:-3])
make_ds = df['화면 크기'].apply(pre_ds).astype(np.float64).round(2)
#웹캠 열 수정
#'○'값은 1로 결측치는 '0'으로 지정.
make_wc = df['웹캠(HD)'].fillna('0').replace('○','1').astype('category')
#광시야각 수정
#'○'값은 1로 결측치는 '0'으로 지정.
make_la = df['광시야각'].fillna('0').replace('○','1').astype('category')
#제조사 열 생성
#제조사는 제품명 모두 맨 앞 단어가 제조사로 되어있는 것으로 판단하여 제품명에서 split[0]으로 추출
def pre_md(md):
return md.split(' ')[0]
make_md = df['제품명'].apply(pre_md).rename('제조사')
#배터리 수정
#배터리에 na값이 있어 -1로 변환해주고 'nWh'형태로 되어 있는 값에서 n만 추출하여 값으로 지정함.
#dtype은 float64로 변환하고 소숫점 2째자리까지만
def pre_bt(bt):
if bt == '0':
return '-1'
else:
return bt[:-2]
make_bt = df['배터리'].fillna('0').apply(pre_bt).rename('배터리(Wh)').astype(np.float64).round(2)
#마지막에 return 값을 pd.concat으로 변환되어 만들어진 list들을 합해줌.
return pd.concat(
[make_md,make_pr,make_usb,make_kg,make_ad,make_hdmi,make_sm,
make_mem,make_mm,make_ds,make_wc,make_la,make_bt,make_wk,
df['CPU 종류'],df['운영체제(OS)'],df['화면 비율'],df['메모리 타입'],df['저장장치 종류'],df['GPU 칩셋']],axis=1)notebooks.info()
#위 코드 출력값
<class 'pandas.core.frame.DataFrame'>
Index: 360 entries, 레노버 아이디어패드 Slim3-15ITL 5D WIN10 16GB램 to 한성컴퓨터 TFX3150U Pro
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 CPU 종류 360 non-null object
1 화면 비율 354 non-null object
2 광시야각 360 non-null object
3 메모리 타입 350 non-null object
4 저장장치 종류 360 non-null object
5 GPU 칩셋 353 non-null object
6 HDMI 360 non-null object
7 가격(원) 360 non-null object
8 화면 크기(인치) 360 non-null object
9 운영체제 360 non-null object
10 메모리(GB) 360 non-null object
11 저장 용량(GB) 360 non-null object
12 웹캠 360 non-null object
13 배터리(Wh) 351 non-null object
14 어댑터(W) 306 non-null object
15 두께(mm) 360 non-null object
16 무게(kg) 360 non-null object
17 USB(개) 360 non-null object
18 방향키(ㅗ형/ㅡ형) 360 non-null object
19 제조사 360 non-null object
dtypes: object(20)
memory usage: 59.1+ KBData Mining
간단하게 가격 확인
total_notebooks = notebooks.index.size
max_price = notebooks['가격(원)'].values.max()
min_price = notebooks['가격(원)'].values.min()
mean_price = notebooks['가격(원)'].values.mean()
print(f'현재 판매중인 전체 {total_notebooks}개의 노트북 중 \n최대가격은 {max_price}원이고\n최소가격은 {min_price}이며,\n평균 판매 금액은 {mean_price.round(2)}원이다.')
#위 출력값
현재 판매중인 전체 360개의 노트북 중
최대가격은 6990000원이고
최소가격은 278990이며,
평균 판매 금액은 1619070.67원이다.세부적으로 가격 확인
# 그룹화 이후 인덱스조정을 위한 함수 설정
def flat_cols(df):
df.columns = ['_'.join(x) for x in df.columns.to_flat_index()]
return df
# 제조사별 가격의 집계함수들을 계산
notebooks_group_1 = (
notebooks.groupby(['제조사'])[['가격(원)']]
.agg(['size', 'max', 'min', 'mean', 'std'])
.pipe(flat_cols)
.reset_index()
)
notebooks_group_1
# 판매수량이 많은순, 최고가격, 최소가격, 가격평균이 큰 순, 가격 표준편차가 높은 순으로 정렬
# 컬럼이름을 변경
sorted_group_1 = notebooks_group_1.sort_values(['가격(원)_size', '가격(원)_max', '가격(원)_min', '가격(원)_mean', '가격(원)_std'],
ascending = [False, False, True, False, False])
sorted_group_1 = sorted_group_1.rename(columns = {'가격(원)_size' : '판매 개수',
'가격(원)_max' : '최고 금액',
'가격(원)_min' : '최소 금액',
'가격(원)_mean' : '가격 평균',
'가격(원)_std' : '가격 표준편차'})
sorted_group_1
fig, ax = plt.subplots(figsize=(20, 10))
plt.grid(linestyle='--')
plt.title('제조사별 가격 평균 시각화')
sns.barplot(x='제조사', y='가격 평균', data=sorted_group_1);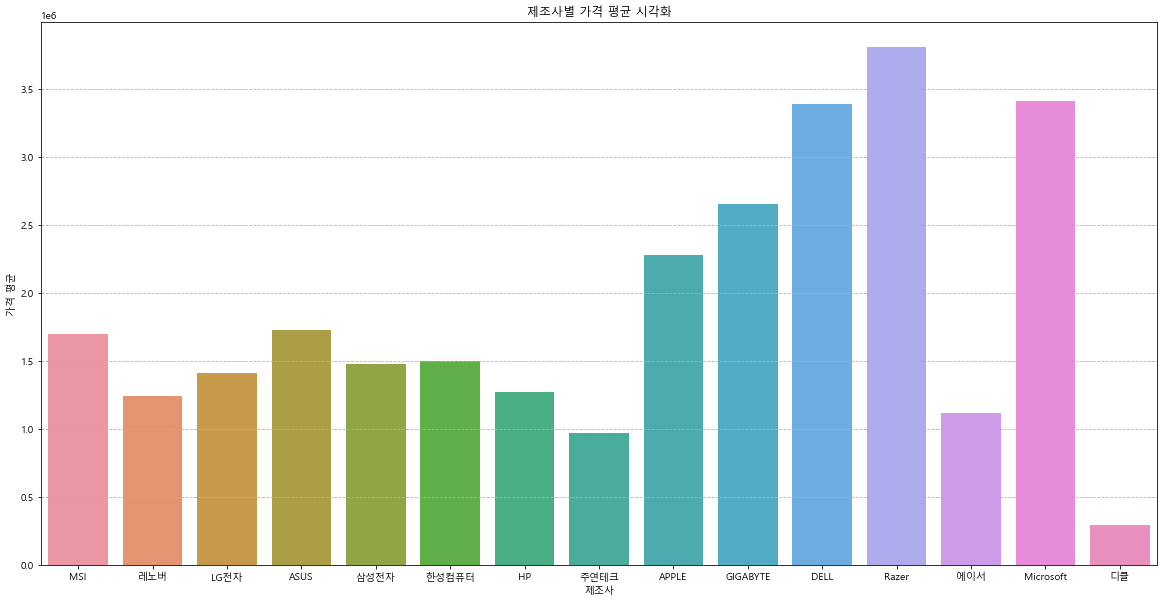
우리에게 익숙한 3개 제조사의 시장 점유율
top3 = sorted_group_1.loc[[5, 11, 0]].set_index('제조사')
top3
ratio = [28.08,71.92]
labels = ['Top3', 'Others']
colors = ['red', 'gray']
explode = [0.10, 0]
fig, ax = plt.subplots(figsize=(10,5))
plt.pie(ratio, labels=labels, autopct='%.1f%%', startangle=260,
explode = explode, counterclock=False, shadow=True, colors=colors)
plt.show()
CPU종류와 GPU종류에 따른 가격
notebooks_group_2 = (
notebooks.groupby(['제조사', 'CPU 종류', 'GPU 칩셋'])[['가격(원)']]
.agg(['max', 'min', 'mean'])
.pipe(flat_cols)
.reset_index(['CPU 종류', 'GPU 칩셋'])
)
notebooks_group_2
제조사별 화면크기 제작 성향 비교
: 전반적인 화면 분포를 확인해보았을때,
제조사별로 최소 13인치 ~ 최대 17인치의 화면을 제작하는 것으로 나타나며
전반적인 화면의 평균값은 15.27인치에 해당한다.
notebooks_group_3 = (
notebooks.groupby('제조사')[['화면 크기(인치)']]
.agg(['max', 'min', 'mean']).round()
.pipe(flat_cols)
)
notebooks_group_3
제조사별 노트북의 무게 비교
: '가벼운 노트북'으로는 LG의 그램으로 대중들에게 익숙하지만,
실제 가벼운 가장 노트북을 가진 제조사는 삼성전자에 해당한다.
또, 전반적인 노트북들의 평균 무게는 1.83kg에 해당한다
notebooks_group_4 = (
notebooks.groupby('제조사')[['무게(kg)']]
.agg(['max', 'min', 'mean']).round(3)
.pipe(flat_cols)
)
notebooks_group_4
3.5. 제조사별 GPU 칩셋 가격 비교
: 제조사별 GPU 칩셋의 값들을 가격이 싼 것부터 나열해봤다.
notebooks.groupby(['제조사','GPU 칩셋'],as_index=False).apply(lambda df: df.sort_values(
'가격',ascending=False
).head(1)
).droplevel(0)
3.6. CPU별 배터리 성능의 가격 비교
: CPU별 배터리 성능의 값들을 가격이 비싼 것부터 나열해봤다.
notebooks.groupby('CPU 종류',as_index=False).apply(lambda df: df.sort_values(
'배터리(Wh)',ascending=False
).head(1)
).droplevel(0).sort_values('가격',ascending=False)
3.7. 가격, 무게, 배터리, 저장 용량, 메모리 들의 상관관계 비교
: 가격과 어떤 요소가 가장 연관이 있는지 중점으로 봤다.
GPU와 가격의 상관성을 비교하고 싶었지만, GPU가 문자열이라 비교하지 못하였다.
fig, ax = plt.subplots(figsize=(8,8))
corr = notebooks[['가격','무게(kg)','배터리(Wh)','저장 용량(GB)','메모리(GB)']].corr()
mask= np.zeros_like(corr,dtype=bool)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(
corr,
mask=mask,
fmt = '.2f',
annot=True,
ax=ax,
cmap='RdBu',
vmin=-1,
vmax=1,
square=True
)
3.8. CPU 종류별 가격 시각화
: CPU 종류별 가격은 어떻게 분포되어있는지 보았다.
코어i7가 M1 PRO보다 더 비싸다는 것을 확인할 수 있었다.
fig, ax = plt.subplots(figsize=(10,8))
plt.bar(notebooks['CPU 종류'],notebooks['가격'])
plt.xticks(rotation=90)
sns.barplot(notebooks['CPU 종류'],notebooks['가격'])
3.9. GPU 칩셋별 가격 시각화
: GPU 칩셋별 가격은 어떻게 분포되어있는지 보았다.
CPU에서는 apple 제품이 다른 제품들에 비해 싼 가격이었지만, GPU에서는 비싼 가격대로 보인다.
fig, ax = plt.subplots(figsize=(10,8))
#plt.bar(notebooks['GPU 칩셋'],notebooks['가격'])
sns.barplot(notebooks['GPU 칩셋'],notebooks['가격'])
plt.xticks(rotation=90)
3.10. 360개의 인기 제품중 인기있는 CPU 종류 시각화
: 360개 인기 제품에서 어떤 CPU가 가장 인기 있는지 확인해 봤다.
인텔에 코어 i7 11세대가 가장 많은 인기를 보여줬다.
#CPU 종류별 인기 제품 포함 개수
fig,ax = plt.subplots(figsize=(10,8))
sns.countplot(y='CPU 종류',data=notebooks,order= notebooks['CPU 종류'].value_counts().index)
3.11. 소비자 선호 조건에 맞는 제품 정렬(boolean 과 mask 활용)
다나와 쇼핌몰에서는 제조사 / CPU 종류 / 화면 크기 / 메모리 / 저장 용량 / 운영체제 / 무게 를 선택하여 볼 수 있다.
하지만, GPU 종류 / 웹캠 유무 / HDMI 포트 유무 / 방향키 종류 / 두께 / 배터리 용량등의 세분화된 스펙은 선택할 수 없다.
boolean 개념과 mask 함수를 통해 선호하는 위 스펙을 선택하면 그에 맞는 스펙의 제품이 정렬될 수 있도록 하는 알고리즘을 만들어 보았다.
- 우선 category 로 변환할 수 있는 condition_category함수
- 연속형 데이터를 범위 지정으로 bool형태로 변환하는 condition_continuous 함수
위 두 함수를 우선적으로 생성하여 각 데이터에 맞는 함수를 적용한다.
#GPU 칩셋ct / 웹캠(HD) ct/ HDMIct / 방향키() ct/ USB cont / 두께 cont/ 배터리cont
#category 데이터 boolean 진행
def condition_category(col_name):
global notebooks
#선택해야할 옵션을 보여주고 input값으로 순번을 선택하여 입력받게한다.
print(pd.DataFrame(notebooks[col_name].value_counts().index,index = [i for i in range(1,len(list(notebooks[col_name].value_counts().index))+1)],columns = [col_name]))
cond = int(input(col_name+'의 번호를 입력하세요. 상관이 없다면 0을 입력하세요 :'))
print('*'*75)
#notebooks[col_name]에 원한 옵션 문자열만 빼고 다 False로 변환, 상관없다고 0을 누를 시 모두 True인 Series인 객체를 통해 다 True로 변환할 수 있도록 함.
condition = notebooks[col_name] == notebooks[col_name].value_counts().index[int(cond)-1] if cond >0 else pd.Series(index=notebooks.index, data=[True for i in range(360)])
return condition
#연속형 데이터 boolean 진행
def condition_continuous(col_name):
global notebooks
#선택해야할 옵션을 보여주고 input값으로 순번을 선택하여 입력받게한다.
print(pd.DataFrame([max(notebooks[col_name]),min(notebooks[col_name])],index = ['max','min'],columns = [col_name]))
cond_h = float(input(col_name+'의 원하는 수치기준(~이상)을 입력하세요. 상관이 없다면 -1을 입력하세요 :'))
cond_l = float(input(col_name+'의 원하는 수치기준(~이하)을 입력하세요. 상관이 없다면 -1을 입력하세요 :'))
print('*'*75)
#notebooks[col_name]에 원한 옵션 조건만 빼고 다 False로 변환, 상관없다고 0을 누를 시 모두 True인 Series인 객체를 통해 다 True로 변환할 수 있도록 함.
if (cond_h == -1.0) & (cond_l == -1.0):
condition = (min(notebooks[col_name]) <= notebooks[col_name]) & (notebooks[col_name] <= max(notebooks[col_name]))
elif (cond_h != -1.0) & (cond_l == -1.0):
condition = (cond_h <= notebooks[col_name]) & (notebooks[col_name] <= max(notebooks[col_name]))
elif (cond_h == -1.0) & (cond_l != -1.0):
condition = (min(notebooks[col_name]) <= notebooks[col_name]) & (notebooks[col_name] <= cond_l)
else:
condition = (cond_h <= notebooks[col_name]) & (notebooks[col_name] <= cond_l)
return condition#bool 형태로 된 condition들을 다 가져와 & 로 묶어서 값들이 condition_final로 객체 할당
condition_final = condition_category('GPU 칩셋')&condition_category('웹캠(HD)')&condition_category('HDMI')&condition_category('방향키(ㅡ형/ㅗ형)')&condition_continuous('USB(개)')&condition_continuous('두께(mm)')&condition_continuous('배터리(Wh)')
#mask함수로 condition_final에서 True인 값들만 추출
notebooks.mask(~condition_final).dropna(how='all').sort_values('가격') #싼 제품부터 정렬되어 나오도록

> 정렬된 제품들이 가독성이 떨어지므로 시각화를 진행해보았다.
#위의 정렬 시각화
def add_value_label(y_list):
for i in range(0,10):
plt.text(i,y_list[i],y_list[i], ha="center")
fig, ax = plt.subplots(figsize=(10,8))
plt.bar(notebooks.mask(~condition_final).dropna(how='all').sort_values('가격')[:10].index,notebooks.mask(~condition_final).dropna(how='all').sort_values('가격')['가격'][:10])
add_value_label(notebooks.mask(~condition_final).dropna(how='all').sort_values('가격')['가격'][:10])
plt.xticks(rotation=90)
'Data_study > DATA_PROJECT' 카테고리의 다른 글
| [Project] 휠체어 목발 이용자 인식 yolo v5 - 2(모델,결과) (0) | 2022.10.04 |
|---|---|
| [Project] 휠체어 목발 이용자 인식 yolo v5 - 1(수집,증강) (0) | 2022.08.20 |
| [Project] kaggle_compitition : Digit Recognizer (0) | 2022.07.10 |